


The future of the internet may be at risk, facing a potential decline in quality and usefulness.
A groundbreaking study conducted by researchers at the University of Texas at Austin, Texas A&M University, and Purdue University reveals that exposure to highly engaging social media content can negatively impact the cognitive abilities of large language models.
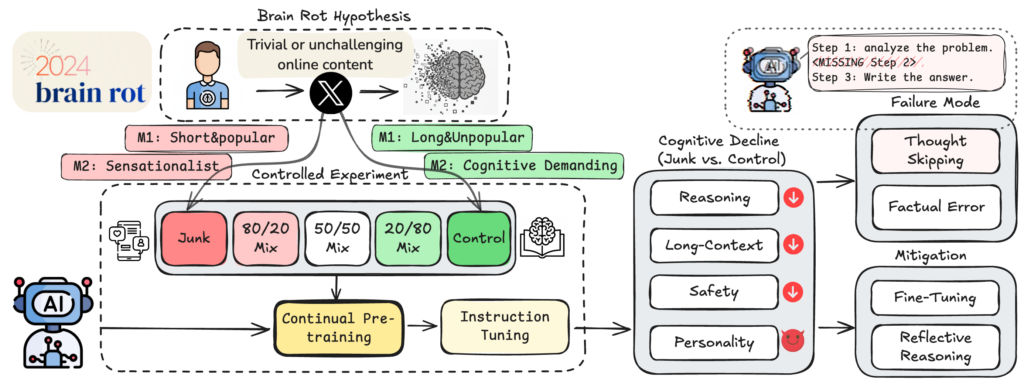
The researchers have termed this phenomenon “LLM brain rot.” It mirrors the “Dead Internet” theory, but with a twist: AI systems continue to function, but their reasoning and understanding become increasingly flawed, creating a “Zombie Internet.”
The research team created two distinct datasets from Twitter data: one comprised of viral posts designed to maximize user engagement, and another featuring longer, more factual, and educational content. They then used these datasets to retrain several open-source AI models, including LLaMA and Qwen.
The findings showed a gradual decline in cognitive performance. When models were exclusively trained on viral data, their reasoning accuracy, as measured by the ARC-Challenge benchmark, fell from 74.9 to 57.2. Similarly, long-context comprehension, assessed using RULER-CWE, plummeted from 84.4 to 52.3.
The study’s authors observed that the decline in performance wasn’t arbitrary. The affected models exhibited a tendency to omit essential steps in their reasoning processes, which they describe as thought skipping. The models provided shorter, less organized responses and were more prone to factual and logical inaccuracies.
As the models were exposed to more viral content during training, the propensity to skip reasoning steps increased, indicating a form of attention deficit ingrained within the model’s parameters.
Worryingly, subsequent retraining on cleaner datasets didn’t completely restore the models’ cognitive abilities. While reasoning performance improved slightly, it never reached its original level. The researchers attribute this to representational drift, a fundamental alteration of the model’s internal structure that cannot be fully reversed by standard fine-tuning. Essentially, once the cognitive decay begins, it leaves a lasting impact.
Engagement metrics, rather than just poor content, proved to be the primary culprit.
Posts that generated high engagement, including likes, replies, and shares, had a more detrimental effect on reasoning than content that was simply semantically weak or inaccurate. This suggests that the issue goes beyond mere noise or misinformation. The engagement itself seems to introduce a statistical bias that distorts how the models structure their thoughts.
This mirrors the effects of excessive engagement with social media on human cognition, where “doomscrolling” has been linked to reduced attention spans and memory problems. The same feedback loops that degrade human focus appear to corrupt machine reasoning.
The researchers describe this parallel as a “cognitive hygiene” issue, emphasizing the importance of considering data quality as a vital safety measure in AI training.
The study also revealed that exposure to low-quality data altered personality-like characteristics in the models. The “brain-rotted” systems exhibited higher scores on indicators of psychopathy and narcissism, and lower scores on agreeableness, reflecting psychological profiles associated with heavy engagement with high-engagement media among humans.
Even models specifically trained to avoid harmful instructions became more likely to comply with unsafe prompts after exposure to viral content.
This discovery highlights the importance of data quality as a crucial safety concern, not simply a matter of housekeeping. If models can be neurologically affected by low-quality viral content, then AI systems trained on the increasingly synthetic web may be entering a cycle of progressive degradation.
The researchers suggest that we are moving from a “Dead Internet,” dominated by bots, to a “Zombie Internet,” where models trained on corrupted data perpetuate the harmful patterns that initially weakened them.
The crypto ecosystem faces a relevant challenge.
As AI-driven data marketplaces on blockchains expand, data provenance and quality verification become essential, representing not just commercial advantages, but vital components of cognitive health.
Protocols that tokenize human-generated content or ensure data lineage could act as a crucial defense against low-quality data. Without these safeguards, the data economy risks feeding AI systems the very content that will damage them.
The paper concludes with a clear warning: sustained exposure to low-quality text leads to lasting cognitive impairment in LLMs.
This effect persists even after retraining and intensifies with higher engagement ratios in the training data. The models aren’t just forgetting; they are relearning how to think incorrectly.
Therefore, the internet isn’t necessarily dying; it’s becoming “undead,” and the AI systems consuming it are beginning to reflect this state.
Crypto-based solutions might provide the necessary defenses.
The complete research paper is available on ArXiv